|
<< Click to Display Table of Contents >> Understanding the problem |
  
|
|
<< Click to Display Table of Contents >> Understanding the problem |
|
The "problem" is how to best support the making of a decision. Let's look at this more closely. The question that is at the front of the mind of every decision-maker is "what can go wrong"? The occurrence of a "bad thing" can be posed as a hypothesis that modelling can attempt to reject, or demonstrate that its probability of occurrence is low. Alternatively, modelling may demonstrate that the probability of a bad thing happening is not low at all, so that an appropriate management "plan B" must be sought. Model predictions are uncertain. Their uncertainties should therefore be analysed so that managers and stakeholders are aware of undesirable consequences of a contemplated management strategy. Ideally, if data allows it, uncertainties should also be reduced so that management does not have to be excessively conservative. It follows that Bayesian analysis (or something that achieves similar outcomes) should accompany model deployment. Furthermore, any aspects of a natural system that may instigate a pessimistic prediction should be represented in a decision-support model. More than this, if these aspects are uncertain, they should be represented as parameters (if possible) so that they can be "wiggled" during uncertainty analysis and constrained during history-match-based uncertainty reduction. If only it were this easy! A lot can go wrong with well-intentioned Bayesian hopes. |
There is a temptation to make numerical models complex because natural systems are complex. Much of this temptation arises from the futile pursuit of simulation integrity. This, in turn, often arises from fear of criticism from stakeholders, academics and/or regulators who perceive "simulation integrity" as (a) attainable and (b) worthwhile. In our view, simulation integrity is not attainable. Furthermore the "worth" of complexity (or any other aspect of model design) must be judged against the decision-support metrics that modelling is meant to serve. For the purpose of the present discussion, modelling complexity can be subdivided into two types. Structural complexityWe use this term to refer to aspects of a model's construction such as: •number of layers; •spatial extent of the model domain; •size of grid cells in different parts of a model domain; •simulated processes (for example unsaturated flow and/or surface water flow); •steady-state or transient. Parameterisation complexityParameters refer to those aspects of a model that are adjustable - during history-matching and during uncertainty analysis. "Parameterisation complexity" refers to parameterisation devices that are used by a model, and ultimately to the number of parameters that are assigned to a model. Facets of model design that it addresses include: •whether spatial parameterisation is based on a limited number of zones, a considerable number of pilot points, or on model cells; •whether unknown historical extraction rates are represented probabilistically (and hence parameterised) or are assumed. Structural complexity and parameterisation complexity are not unrelated. For example it makes little sense to endow a structurally complex model with a simplistic parameterisation scheme. Let us not forget the metrics of decision-support modelling, and in particular the necessity to avoid decision-support modelling failure. If processes are deemed important enough to simulate, it is because failure to represent them may bias decision-critical model predictions. The same applies to representation of earth properties that govern these processes. The fact that these may be poorly known is no reason to assume that they are homogeneous. |
Complex models often run slowly. Their numerical stability is often problematical. So they often do not work well with programs of the PEST and PEST++ suites. Uncertainty quantification and reduction can therefore become numerically expensive at best, and impossible at worst. Structurally complex models are complex because they simulate spatial, temporal and process detail. Herein lies a paradox. By definition, structure is rigid. In contrast, our knowledge of detail is limited. Ideally, detail should therefore be expressed stochastically, and hence parametrically, in order to avoid predictive bias and/or underestimation of predictive uncertainty. Of course, parametric representation of detail requires model abstraction. This too can engender predictive bias. So compromises must be made. (And let us not forget that, without a model grid, there is no solution of partial differential equations.) However it is incurred, the potential for predictive bias must be included in quantified predictive uncertainty. This may not be straightforward. Uncertainty may need to be inflated in order to preclude decision-support modelling failure. Parametric complexity, as an adjunct to structural complexity, may engender predictive bias in other, more subtle ways. Suppose that we are calibrating a complex, multi-layered model. History-matching may dictate that hydraulic conductivity be increased in certain parts of the model domain in order for model outputs to replicate locally low horizontal hydraulic gradients. So should hydraulic conductivity be increased in the first layer? In the second layer? In all layers? It is the prior parameter probability distribution which decides where information that is harvested from a history-matching dataset must flow. If it flows to the wrong place, some model predictions may be biased. So, in summary, a high level of structural complexity requires the making of many assumptions. It must be accompanied by an even higher level of parameterisation complexity and by an accompanying prior parameter probability distribution. More assumptions are therefore required. Assumptions run the risk of inducing predictive bias. |
Can parameters be substituted for structure? Sometimes this may be possible. For example, rather than explicitly represent a fault that may hydraulically connect two layers in an unstructured grid multilayer model, can the aquitard that separates these layers be parameterised in such a way as to simulate this connection? This may be useful if: •we do not know whether the connection is strong or not; •we do not know exactly where the fault is; •we do not know exactly the length over which the possible hydraulic connection occurs. This strategy grants adjustability to something that we do not know exactly. At the same time, structural complexity is reduced. Smaller model run times and enhanced model numerical stability facilitate parameter adjustment during history-matching and uncertainty analysis. PLPROC supports parameteriseable, moveable geobodies and non-stationary anisotropy that facilitate parametric representation of structural features. A model's parameters can be considered as receptacles for information. Prior to history-matching they hold probabilistic information that emerges from site characterisation. During history-matching these probability distributions are constrained as they receive information from measurements of system behaviour. Despite the ability of parameters to harvest information and proclaim information insufficiency through uncertainty analysis, assigning prior probability distributions to parameters that may be surrogates for structure can sometimes be problematic. As stated above, an erroneous prior may result in misdirection of harvested information, and therefore promote predictive bias. At the same time, while model abstraction based on a design concept of reduced structural complexity and enhanced parameterisation complexity may assist the harvesting of information from data, it may be harder for non-experts to make linkages between history-matched model components and their real world counterparts. Decision-support modelling requires many compromises. |
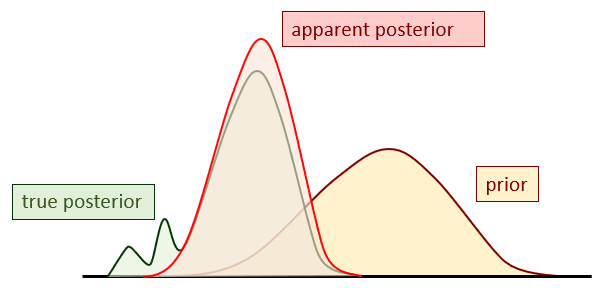
Once a decision is made, and a new groundwater management regime is established, the last thing that anyone wants is an unpleasant surprise. Uncertainty analysis is supposed to prevent this. However, the key word here is "unpleasant". This means that it is the pessimistic end of a predictive probability distribution that is of most interest. Recognition of this can reduce the decision-support workload considerably. There are two reasons for this. Firstly, a full Bayesian analysis becomes unnecessary. The important thing is worst case scenario analysis. This is difficult enough, given the necessity for it to be history-match constrained. But it may be easier than examining the entirety of a posterior predictive probability distribution. Secondly, the nature of geological media is such that an unwanted predictive outcome may be induced by sedimentary, diagenetic or structural features whose existence, locations, and properties are difficult to characterise probabilistically. It follows that the management consequences of their existence can then be explored in ways that do not require a great deal of statistical sophistication. The posterior probability of a prediction of management interest may therefore look less like the classical textbook outcomes of Bayesian analysis, and more like the figure below.
The pessimistic end of a posterior predictive probability distribution.
|