|
<< Click to Display Table of Contents >> Generating random numbers |
  
|
|
<< Click to Display Table of Contents >> Generating random numbers |
|
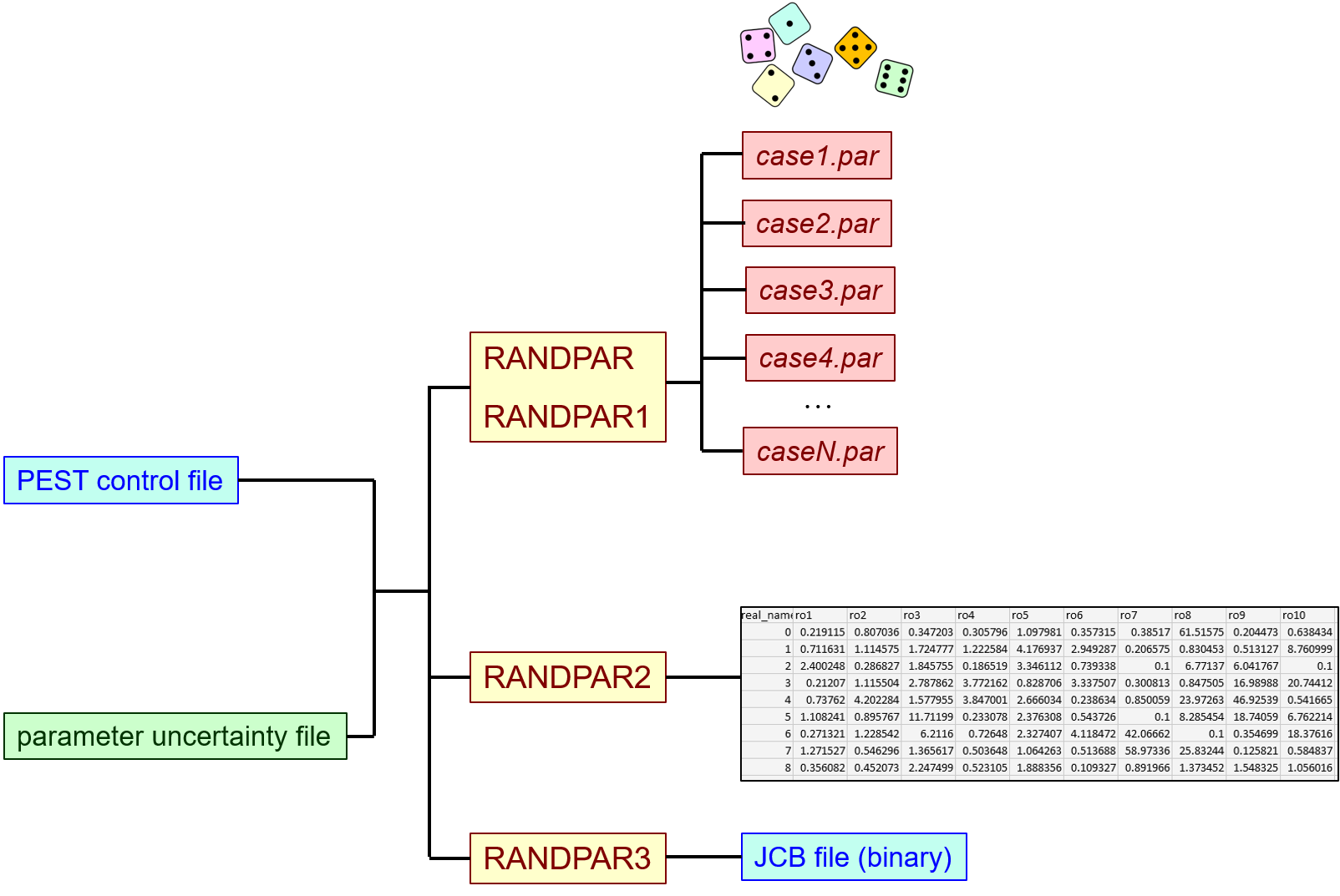
RANDPAR*RANDPAR1, RANDPAR2, RANDPAR3 and RANDPAR4 are supplied with PEST. "RANDPAR" stands "random parameter". Except for RANDPAR4, these utility programs perform similar roles to each other. These roles are summarised in the following table. All of these programs obtain information on parameter uncertainty by reading the contents of a parameter uncertainty file. This is the same file that is read by many PEST utilities that undertake linear uncertainty analysis. If parameterisation is based on pilot points, members of the PPCOV family can be used to write covariance matrix files that are cited in parameter uncertainty files.
A parameter value file is exemplified below.
A parameter value file finds many uses. PEST records optimised parameters in a parameter value file; the file is updated during ever iteration of the inversion process. The PARREP utility inserts parameter values that are stored in a parameter value file into a PEST control file as initial parameter values in that file. As stated in the above table, both RANDPAR and RANDPAR1 record the random parameter values that they generate in a series of parameter value files. These files have indices built into their names, for example case1.par, case2,par ... caseN.par. Model runs can be commissioned that use all of these parameter sets.
RANDOBSRANDOBS supports the use of PESTPP-IES and RSI_HP. RANDOBS uses observation weights that are recorded in the "observation data" section of a PEST control file to generate random realisations of measurement noise, which are then added to observations. These are stored in a CSV or JCB file. |
The groundwater utility suite provides a family of programs whose names begin with "FIELDGEN". These programs generate stochastic fields on a cell-by-cell basis. Some of them are MODFLOW-specific. Others generate stochastic fields at points which can be the centres of cells of an arbitrary grid, structured or unstructured, two-dimensional or three-dimensional. Members of this family are listed in the following table.
The oldest of these programs is FIELDGEN. It uses the sequential Gaussian methodology. A benefit of this methodology is that it is easy to condition stochastic fields using point measurements of hydraulic properties; the stochastic field respects these measurements at measurement points. FIELDGEN records the stochastic field that it generates in a MODFLOW-compatible real array. The moving average method does not allow such easy conditioning. However, conditioning can be achieved in other ways. A benefit of the moving average method is that it is particularly easy to program. It is also particularly easy to generate stochastic fields whose statistical properties vary from point to point throughout a model domain. These statistical properties include correlation length, variance, anisotropy and direction of anisotropy. Programs in the above table other than FIELDGEN store the stochastic fields that they generate in CSV of binary files. CSV files can be read by PLPROC where they can then be re-written in model-ready format. The FIELDGEN2D_SVA1 and FIELDGEN3D_SVA1 utilities provide even more flexibility. They enable so-called "hierarchical inversion" where spatially-varying hyperparameters which describe earth property geostatistics can be estimated at the same time as the properties themselves. This is very powerful stuff!! |